在現代物業管理中,系統化的工作流程和高效的信息系統集成是提升服務質量和效率的關鍵。本文將全面介紹物業日常服務的常用工作流程圖,并探討信息系統如何集成這些流程,以實現智能化管理。
一、物業日常服務常用工作流程圖大全
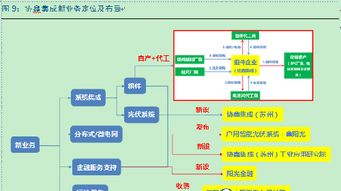
物業日常服務涵蓋多個方面,包括保安、保潔、維修、客戶服務等。以下是一些核心工作流程的簡要流程圖描述:
- 報修服務流程圖:
- 開始:業主通過電話、App或前臺提交報修請求。
- 步驟1:物業客服接收并記錄信息,生成工單。
- 步驟2:調度員分配維修人員,并通知業主預計處理時間。
- 步驟3:維修人員現場檢查并修復問題。
- 步驟4:完成后,業主確認并反饋滿意度。
- 結束:工單歸檔,數據更新。
- 保安巡邏流程圖:
- 開始:制定每日巡邏計劃。
- 步驟1:保安人員按路線巡邏,檢查安全隱患。
- 步驟2:發現問題,立即上報并記錄。
- 步驟3:處理緊急事件或協調相關部門。
- 步驟4:巡邏結束,提交報告。
- 結束:數據匯總,用于優化計劃。
- 保潔服務流程圖:
- 開始:制定保潔日程表。
- 步驟1:保潔人員分區作業,清潔公共區域。
- 步驟2:檢查清潔質量,處理垃圾。
- 步驟3:定期深度清潔和消毒。
- 步驟4:反饋問題,調整計劃。
- 結束:記錄完成情況,確保環境整潔。
- 客戶服務流程圖:
- 開始:業主咨詢或投訴。
- 步驟1:客服接收并分類問題。
- 步驟2:根據類型,轉交相關部門處理。
- 步驟3:跟蹤處理進度,及時回復業主。
- 步驟4:問題解決后,收集反饋。
- 結束:歸檔案例,改進服務。
這些流程圖通過標準化步驟,減少了人為錯誤,提高了響應速度。在實際應用中,物業公司可以結合自身需求,繪制詳細的流程圖,并張貼在辦公區域,方便員工參考。
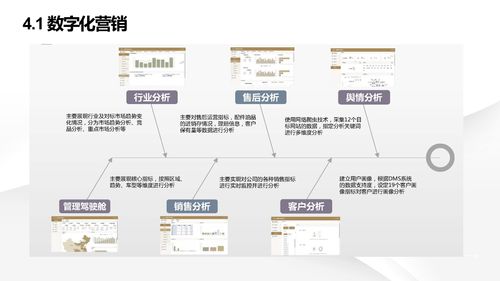
二、信息系統集成服務在物業管理中的應用
隨著科技發展,信息系統集成已成為物業管理的核心支撐。它通過整合各類軟件和硬件,實現數據共享和自動化處理,提升整體效率。
- 信息系統集成的核心功能:
- 數據整合:將報修、保安、保潔等流程數據集中管理,避免信息孤島。
- 自動化調度:基于AI算法,自動分配任務給合適人員,減少人工干預。
- 實時監控:通過傳感器和攝像頭,集成安防系統,實時警報和處理事件。
- 移動端支持:業主可通過App提交請求,員工使用移動設備接收指令,提升便捷性。
- 集成流程示例:
- 以報修服務為例,信息系統集成后,業主在App提交報修,系統自動生成工單,并根據維修人員位置和技能智能分配。維修完成后,系統自動發送反饋問卷,并更新數據庫。
- 在保安巡邏中,集成GPS和監控系統,自動記錄巡邏軌跡,異常事件實時推送至管理中心。
- 優勢與挑戰:
- 優勢:提高服務響應速度、降低運營成本、增強業主滿意度、支持數據分析以優化決策。
- 挑戰:初始投資高、需要員工培訓、數據安全和隱私保護需加強。
物業日常服務的工作流程圖是管理的基礎,而信息系統集成則將這些流程數字化、智能化。隨著物聯網和人工智能的普及,物業管理將更加高效和人性化。建議物業公司盡早規劃和實施信息系統集成,以適應市場變化。